Resiliency and Recovery
Resiliency
High Availability
Redundancy doesn’t mean always available
- May need to be powered on manually
HA (high availability)
- always on, always available
May include many components working together
- Active can provide scalability advantages
Higher availability almost always means higher costs
- There’s always another contingency you could add
- Upgraded power, high-quality server components, etc.
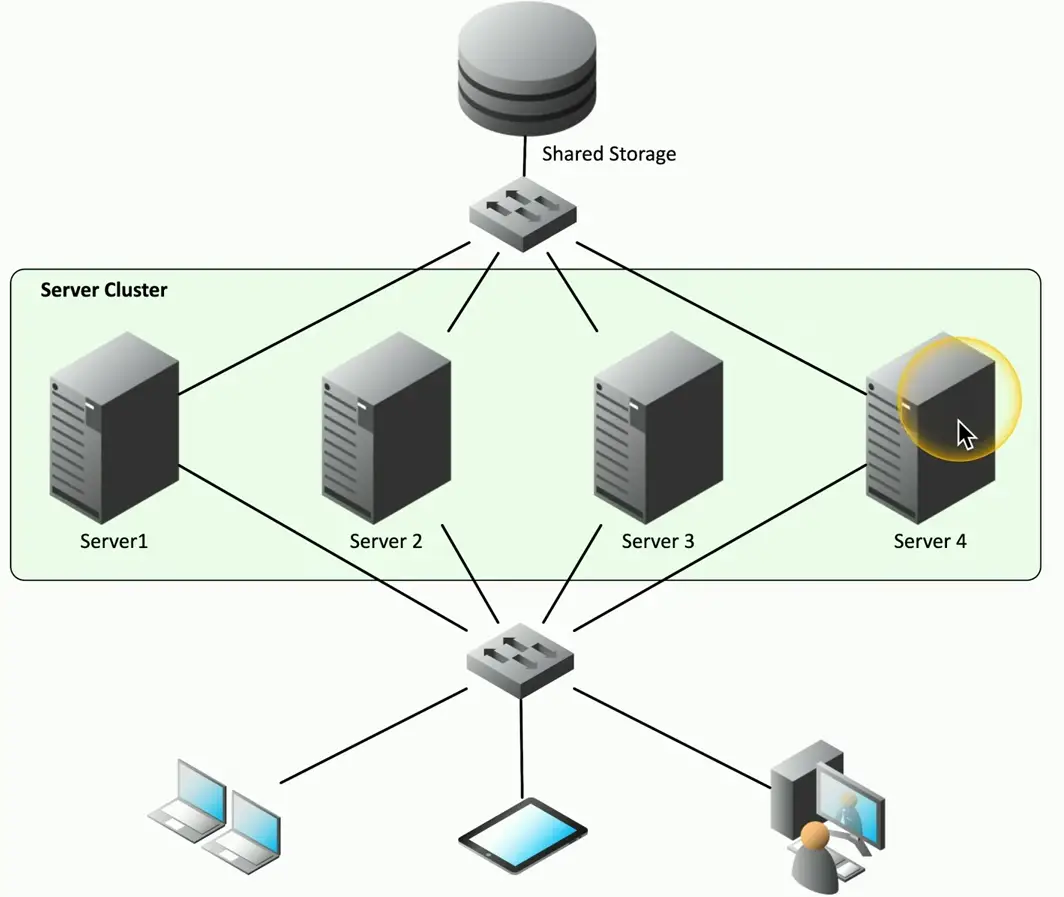
Server Clustering
Combine two or more servers
- Appears and operates as a single large server
- Users only see one device
Easily increase capacity and availability
- Add more servers to the cluster
Usually configured in the OS
- All devices in the cluster commonly use the same OS
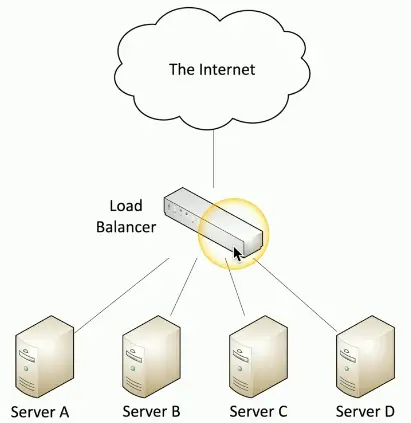
Load Balancing
Load is distributed across multiple servers
- The servers are often unaware of each other
Distribute the load across multiple devices
- Can be different OSes
The load balancer adds or removes devices
- Add a server to increase capacity
- Remove any servers not responding
Site resiliency
Recovery site is prepped
- Data is synchronized
A disaster is called
- Business processes failover to the alternate processing site
Problem is addressed
- This can take hours, weeks, or longer
Revert back to the primary location
- The process must be documented for both directions
Hot Site
An exact replica
- Duplicate everything
Stocked with hardware
- Constantly updated
- You buy two of everything
Applications and software are constantly updated
- Automated replication
Flip a switch and everything moves
- This may be quite a few switches
Cold Site
No hardware
- Empty building
No data
- Bring it with you
No people
- Bus in your team
Warm Site
Somewhere between cold and hot
- Just enough to get going
Big room with rack space
- You bring the hardware
Geographic Dispersion
These sites should be physically different from the organization’s primary location
- Many disruptions can affect a large area
- Hurricane, tornado, floods, etc.
Can be a logistical challenge
- Transporting equipment
- Getting employee’s on-site
- Getting back to the main office
Platform Diversity
Every OS contains potential security issues
- You can’t avoid them
Many security vulnerabilities are specific to a single OS
- Windows vulnerabilities don’t commonly affect Linux or macOS
- And vice versa
Use many platforms
- Different applications, clients, and OSes
- Spread the risk around
Multi-Cloud Systems
There are many cloud providers
- Amazon Web Services, Microsoft Azure, Google Cloud, etc.
Plan for cloud outages
- These can sometimes happen
Data is both geographically dispersed and cloud service dispersed
- A breach with one provider would not affect the others
- Plan for every contingency
Continuity of Operations Planning (COOP)
Not everything goes according to plan
- Disaster can cause a disruption to the norm
We rely on our computer systems
- Technology is pervasive
There need to be an alternative
- Manual transactions
- Paper receipts
- Phone calls for transactions approvals
These must be documented and tested before a problem occurs
Capacity Planning
Match supply to the demand
- This isn’t always an obvious equation
Too much demand
- Application slowdowns and outages
Too much supply
- You’re paying too much
Requires a balanced approach
- Add the right amount of people
- Apply appropriate technology
- Build the best infrastructure
People
Some services require human intervention
- Call center support lines
- Technology services
Too few employees
- Recruit new staff
- It may be time-consuming to add more staff
Too many employees
- Redeploy to other parts of the organization
- Downsize
Technology
Pick a technology that can scale
- Not all services can easily grow and shrink
Web services
- Distribute the load across multiple web services
Database services
- Cluster multiple SQL servers
- Split the database to increase capacity
Cloud services
- Services on demand
- Seemingly unlimited resources (if you pay the money)
Infrastructures
The underlying framework
- Application servers, network services, etc.
- CPU, network, storage
Physical devices
- Purchase, configure, and install
Cloud-based devices
- Easier to deploy
- Useful for unexpected capacity changes
Recovery Testing
Test yourselves before an actual event
- Scheduled updates sessions (annual, semi-annual, etc.)
Use well-defined rules of engagement
- Don’t touch the production systems
Very specific scenario
- Limited time to run the event
Evaluate response
- Document and discuss
Tabletop Exercises
Performing a full-scale disaster drill can be costly
- And time-consuming
Many of the logistics can be determined through analysis
- You don’t physically have to go through a disaster or drill
Get key players together for a tabletop exercise
- Talk through a simulated disaster
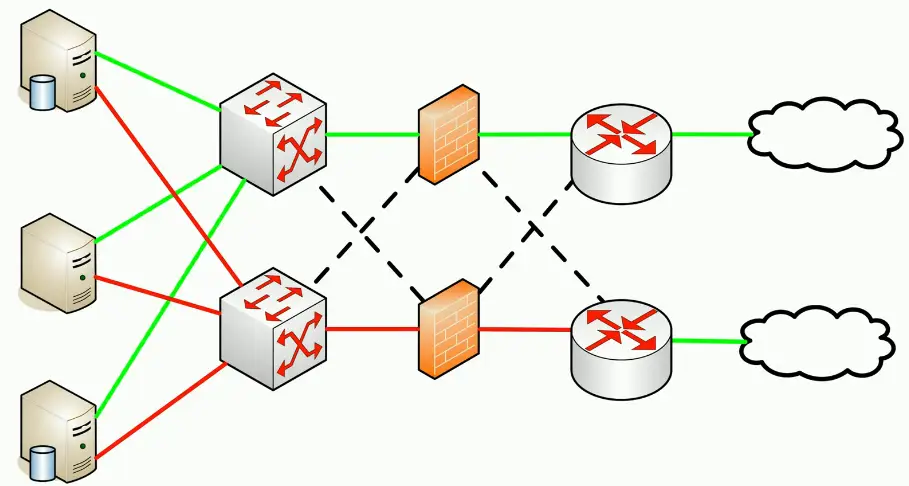
Fail Over
A failure is often inevitable
- It’s “when”, not “if”
We may be able to keep running
- Plan for the worst
Create a redundant infrastructure
- Multiple routers, firewalls, switches, etc.
If one stops working, fail over to the operational unit
- Many infrastructure devices and services can do this automatically
Simulation
Test with a simulated event
- Phishing attack, password requests, data breaches
Going phishing
- Create a phishing email attack
- Send to your actual user community
- See who bites
Test internal security
- Did the phishing get past the filter
Test the users
- Who clicked?
- Additional training may be required
Parallel Processing
Split a process through multiple (parallel) CPUs
- A single computer with multiple CPU cores or multiple physical CPUs
- Multiple computers
Improved performance
- Split complex transactions across multiple processors
Improved recover
- Quickly identify a faulty system
- Take the faulty device out of the list of available processors
- Continue operating with the remaining processors
Backups
Incredibly important
- Recover important and valuable data
- Plan for disaster
Many implementations
- Total amount of data
- Type of backup
- Backup media
- Storage location
- Backup and recovery software
- Day of the week
Onsite vs. Offsite Backups
Onsite backups
- No Internet link required
- Data is immediately available
- Generally less expensive than offsite
Offsite backups
- Transfer data over Internet or WAN link
- Data is available after a disaster
- Restoration can be performed from anywhere
Organizations often use both
- More copies of the data
- More options when restoring
Frequency
How often to back up
- Every week, day, hour?
This may be different between systems
- Some systems may not change much each day
May have multiple backups sets
- Daily, weekly, and monthly
This requires significant planning
- Multiple backup sets across different days
- Lots of media to manage
Encryption
A history of data is on backup media
- Some of this media may be offsite
This makes it very easy for an attacker
- All the data is in one place
Protect backup data using encryption
- Everything on the backup media is unreadable
- The recovery key is required to restore the data
Especially useful for cloud backups and storage
- Prevent anyone from eavesdropping
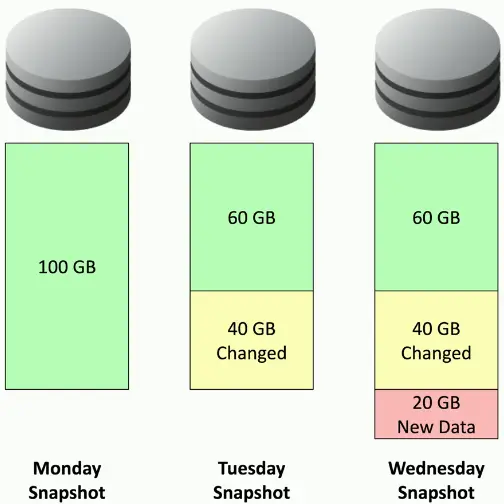
Snapshots
Became popular on virtual machines
- Very useful in cloud environments
Take a snapshot
- An instant backup of an entire system
- Save the current configuration and data
Take another snapshot after 24 hours
- Contains only the changes between snapshots
Take a snapshot every day
- Revert to any snapshot
- Very fast recovery
Recovery Testing
It’s not enough to perform the backup
- You have to be able to restore
Disaster recovery testing
- Simulate a disaster situation
- Restore from backup
Confirm the restoration
- Test the restored application and data
Perform periodic audits
- Always have a good backup
- Weekly, monthly, quarterly checks
Replication
An ongoing, almost real-time backup
- Keep data synchronized in multiple locations
Data is available
- There’s always a copy somewhere
Data can be stored locally to all users
- Replicate data to all remote sites
Data is recoverable
- Disasters can happen at any time
Journaling
Power goes out while writing data to storage
- The stored data is probably corrupted
Recovery could be complicated
- Remove corrupted files, restore from backup
Before writing to storage, make a journal entry
- After the journal is written, write the data to storage
After the data is written to storage, update the journal
- Clear the entry and get ready for the next
Power Resiliency
Power is the foundation of our technology
- It’s important to properly engineer and plan for outages
We usually don’t make our own power
- Power is likely provided by third-parties
- We can’t control power availability
There are ways to mitigate power issues
- Short power outages
- Long-term power issues
UPS
Uninterruptible Power Supply
- Short-term backup power
- Blackouts, brownouts, surges
UPS types
- Offline/Standby UPS
- Line-interactive UPS
- On-line/Double-conversion UPS
Features
- Auto shutdown, battery capacity, outlets, phone line suppression
Generators
Long-term power backup
- Fuel storage required
Power an entire building
- Some power outlets may be marked as generator-powered
It may take a few minutes to get the generator up to speed
- Use a battery UPS while the generator is starting